# packages needed to run the code in this section# !pip install pandas numpy matplotlib seaborn statsmodelimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsimport statsmodels.api as smfrom matplotlib import rc# data pathpath ='../data/'file_name ='deprivation.csv'# import datadf = pd.read_csv(f"{path}{file_name}")# set plot stylesns.set_style('whitegrid')# set plot fontrc('font',**{'family':'sans-serif','sans-serif':['Arial']})# set plot colour palettecolours = ['#1C355E', '#00A499', '#005EB8']sns.set_palette(sns.color_palette(colours))
Linear regression is a cornerstone of data science and statistical inference, and is almost certainly the most common statistical method in use today (t-tests might run it close in industry). Its popularity is owed to its incredible flexibility and simplicity, as it can be used to model a wide range of relationships in a variety of contexts, and it is both simple to use and to interpret. If there is one statistical method that every data scientist and analyst should be familiar with, it is linear regression (followed closely by logistic regression, which is closely related).
Not only is linear regression a phenomenally useful tool in a data scientist’s arsenal, but it is also a fantastic way to learn about the fundamentals of statistical inference. Linear regression serves as the perfect introduction to statistical inference, and it is a great starting point for learning about regression analysis because so many regression models are based on linear regression. Once you have a good understanding of linear regression, you can then move on to more advanced regression models, such as logistic regression, Poisson regression, and so on.
For a really good, accessible introduction to linear regression, I’d highly recommend Josh Starmer’s StatQuest video on the topic:
This tutorial will introduce you to linear regression in Python, using data pulled from two different sources. The first data source is the Public Health England’s Fingertips API. The data included in this tutorial relates to health outcomes (life expectancy at birth) and deprivation (Indices of Multiple Deprivation (IMD) score and decile). The second data source is the Office of National Statistics’ Health Index, which is a composite measure of the health of the population in England. The Health Index is derived from a wide range of indicators related to three health domains: Healthy People (health outcomes), Healthy Lives (health-related behaviours and personal circumstances), and Healthy Places (wider drivers of health that relate to the places people live). The data included in this tutorial comes from two composite sub-domains in the Healthy Lives domain, which measure the physiological and behavioural risk factors that are associated with poor health outcomes. Both data sources are aggregated at the upper-tier local authority level, and the data covers the years 2015 to 2018.
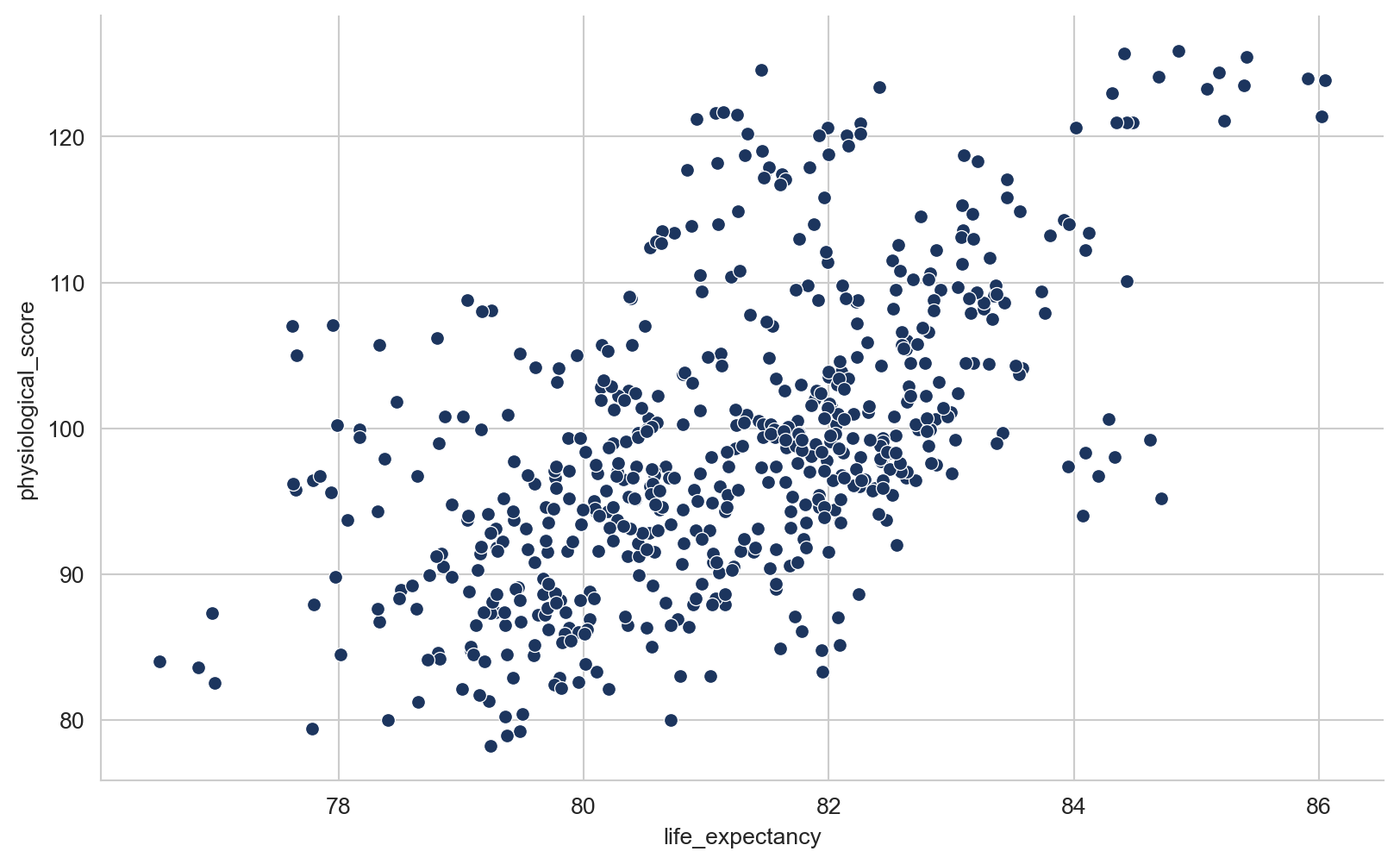
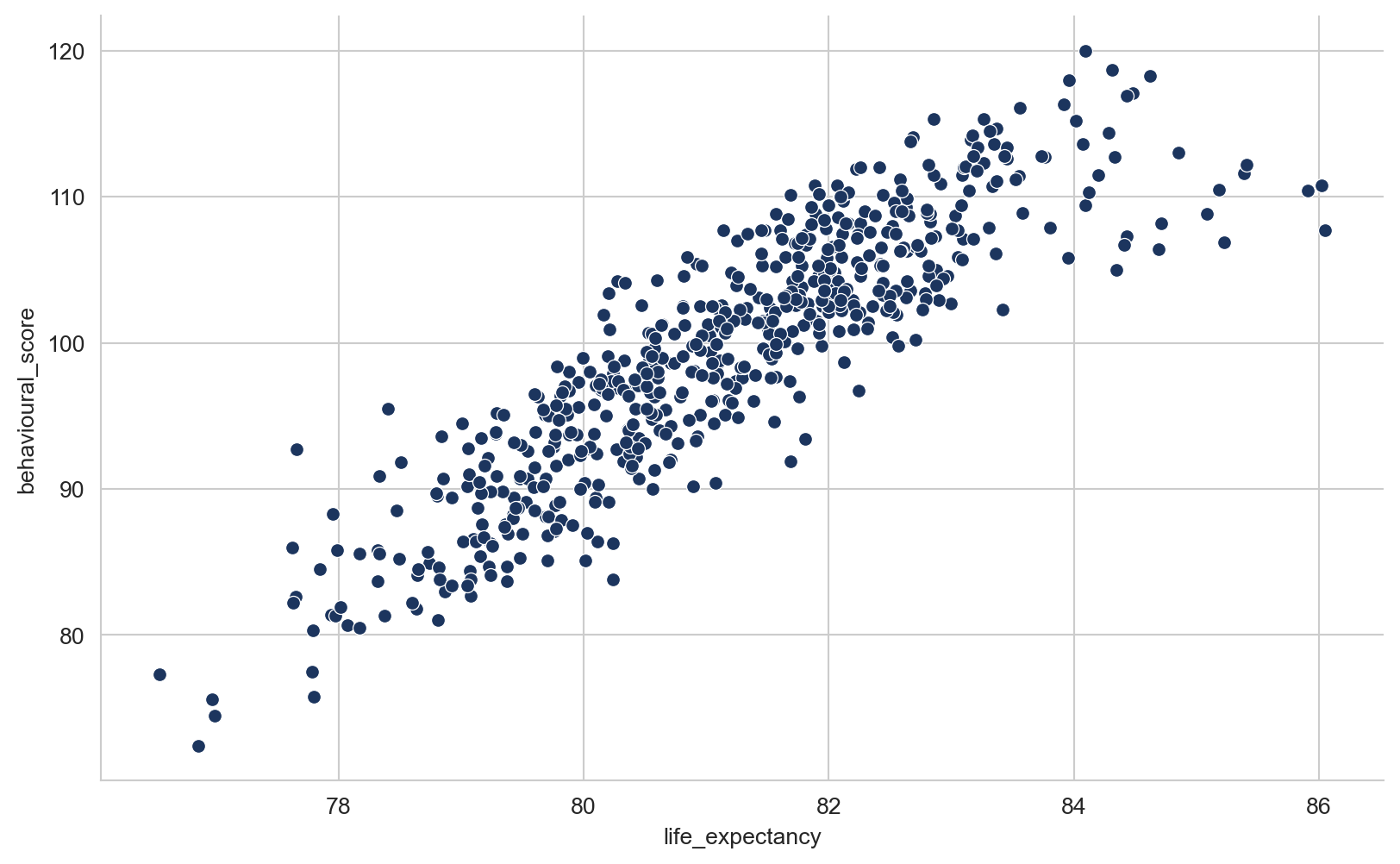
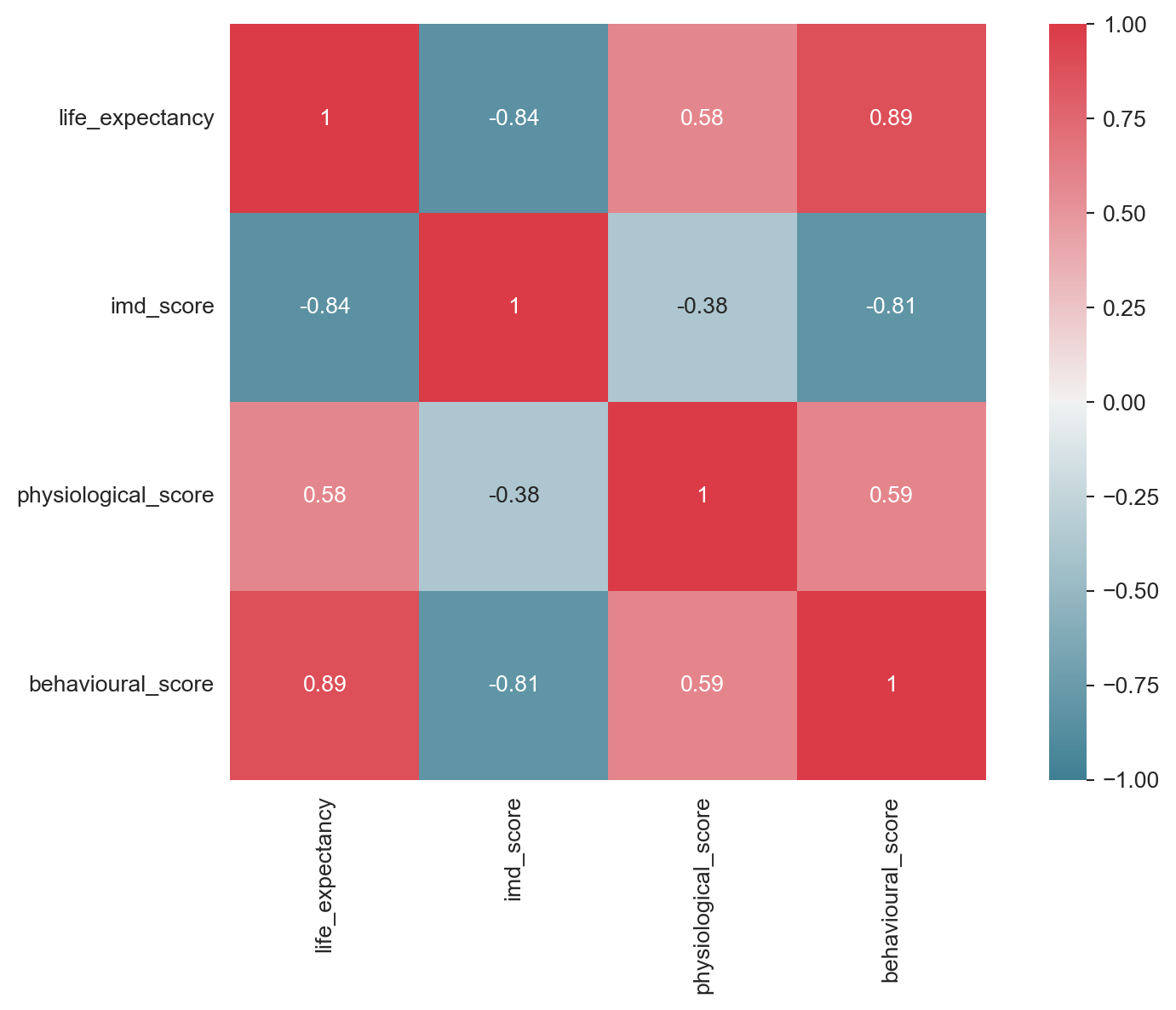
There are strong correlations between life expectancy and the three independent variables, however, the correlation between IMD score and the two risk factor variables is also relatively strong, and in the case of behavioural risk factors, it is very strong. This could be an issue.
OLS Regression Results
==============================================================================
Dep. Variable: life_expectancy R-squared: 0.844
Model: OLS Adj. R-squared: 0.843
Method: Least Squares F-statistic: 1042.
Date: Fri, 16 Feb 2024 Prob (F-statistic): 7.23e-233
Time: 11:52:46 Log-Likelihood: -564.29
No. Observations: 583 AIC: 1137.
Df Residuals: 579 BIC: 1154.
Df Model: 3
Covariance Type: nonrobust
=======================================================================================
coef std err t P>|t| [0.025 0.975]
---------------------------------------------------------------------------------------
Intercept 71.5915 0.623 114.851 0.000 70.367 72.816
imd_score -0.0775 0.006 -13.583 0.000 -0.089 -0.066
physiological_score 0.0238 0.003 7.141 0.000 0.017 0.030
behavioural_score 0.0907 0.006 15.020 0.000 0.079 0.103
==============================================================================
Omnibus: 171.707 Durbin-Watson: 0.765
Prob(Omnibus): 0.000 Jarque-Bera (JB): 611.061
Skew: 1.343 Prob(JB): 2.04e-133
Kurtosis: 7.236 Cond. No. 3.36e+03
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
[2] The condition number is large, 3.36e+03. This might indicate that there are
strong multicollinearity or other numerical problems.
7.3 Evaluating and Interpreting Regression Models
When we fit a regression model, we have to consider both how well the model fits the data (evaluation) and the influence that each explanatory variable is having on the outcome (interpretation). The evaluation process is making sure that the model is doing a good enough job that we can reasonably draw some conclusions from it, while the interpretation process is understanding the conclusions we can draw. It’s important to understand the purpose that both of these processes serve, and to understand that the evaluation process is just kicking the tires, while what we are ultimately concerned with is the interpretation.
There are several elements to consider when interpreting the results of a linear regression model. Broadly speaking the focus should be on the magnitude and the precision of the model coeffficients. The magnitude of the coefficients indicates the strength of the association between the explanatory variables and the outcome variable, while the precision of the coefficients indicates the uncertainty in the estimated coefficients. We use the regression model coefficients to understand the magnitude of the effect and standard errors (and confidence intervals) to understand the precision of the effect.
7.3.1 Model Evaluation
There are a number of ways we might evaluate model performance, but the starting point should be the model’s \(R^2\) and the p-values of the model coefficients. These can help us consider whether the model fits the data and whether we have enough data to trust the conclusions we can draw from each explanatory variable.
7.3.1.1\(R^2\)
The \(R^2\) value is the proportion of the variance in the outcome that is explained by the model. It is often used as a measure of the goodness of fit of the model, and by extension the extent to which the specified model explains the outcome, but caution should be applied when using \(R^2\) this way, because \(R^2\) can be misleading and doesn’t always tell the whole story. One of the main problems with \(R^2\) when used in an inferential context is that adding more variables to the model will always increase the \(R^2\) value, even if the new variables are not actually related to the outcome. Adjusted \(R^2\) values are used to account for this problem, but they don’t resolve all issues with \(R^2\), so it is important to consider \(R^2\) as just one of a number of indicators of the model’s fit. If the \(R^2\) is high, this doesn’t necessarily mean that the model is a good fit for the data, but if the \(R^2\) is particularly low, this might be a good indication that the model is not a good fit for the data, and at the very least it is good reason to be cautious about the results of the analysis, and to take a closer look at the model and the data to understand why the \(R^2\) is so low.
Defining high/low \(R^2\) values is dependent on the context of the analysis. The theory behind the model should inform our expectations about the \(R^2\) value, and we should also consider the number of explanatory variables in the model (adding variables to a regression will increase the \(R^2\)). If the theory suggests that the model should explain a small amount of the variance in the outcome, and the model has only a few explanatory variables, then a low \(R^2\) value might not be a cause for concern.
The Adjusted \(R^2\) value for the above regression model is 0.843, which means that the model explains 84.3% of the observed variance in life expectancy in our dataset. This is a relatively high \(R^2\) value.
7.3.1.2 P-Values
P-values are the probability of observing a coefficient as large as the estimated coefficient for a particular explanatory variable, given that the null hypothesis is true (i.e. that the coefficient is equal to zero), indicating that no effect is present. This can be a little tricky to understand at first, but a slightly crude way of thinking about this is that p-values are an estimate of the probability that the model coefficient you observe is actually distinguishable from zero.
P-values are used to test the statistical significance of the coefficients. If the p-value is less than the significance level then the coefficient is statistically significant, and we can reject the null hypothesis that the coefficient is equal to zero. If the p-value is greater than the significance level, then the coefficient is not statistically significant, and we cannot reject the null hypothesis that the coefficient is equal to zero. The significance level is often set at 0.05, which means that we are willing to accept a 5% chance of incorrectly rejecting the null hypothesis. This means that if the p-value is less than 0.05, then there is a greater than 95% probability that the coefficient is not equal to zero. However, the significance level is a subjective decision, and can be set at any value. For example, if the significance level is set at 0.01, then we are willing to accept a 1% chance of incorrectly rejecting the null hypothesis.
In recent years p-values (and the wider concept of statistical significance) have been the subject of a great deal of discussion in the scientific community, because there is a belief among many practitioners that a lot of scientific research places too much weight in the p-value, treating it as the most important factor when interpreting a regression model. I think this perspective is correct, but I think dismissing p-values entirely is a mistake too. The real problem is not with p-values themselves, but with the goal of an analysis being the identification of a statistically significant effect.
I think the best way to think about p-values is the position prescribed by Gelman, Hill, and Vehtari (2020). Asking whether our coefficient is distinguishable from zero is the wrong question. As analysts, we should typically know enough about the context we are studying to build regression models with explanatory variables that will some effect. The question is how much. A statistically insignificant model coefficient is less a sign that a variable has no effect, and more a sign that there is insufficient data to detect a meaningful effect. If our model coefficients are not statistically significant, it is simply a good indication that we need more data. If the model coefficients are statistically significant, then our focus should be on interpreting the coefficients, not on the p-value itself.
7.3.2 Model Interpretation
Model interpretation is the process of understanding the influence that each explanatory variable has on the outcome. This involves understanding the direction, the magnitude, and the precision of the model coefficients. The coefficients themselves will tell us about direction and magnitude, while the standard errors and confidence intervals will tell us about precision.
7.3.2.1 Model Coefficients
The model coefficients are the estimated values of the regression coefficients, or the estimated change in the outcome variable for a one unit change in the explanatory variable, while holding all other explanatory variables constant. The intercept is the estimated value of the outcome variable when all of the explanatory variables are equal to zero (or the baseline values if the variables are transformed).
A regression’s coefficients are the most important part of interpreting the model. They specify the association between the explanatory variables and the outcome, telling us both the direction and the magnitude of the association. The direction of the association is indicated by the sign of the coefficient (positive = outcome increases with the explanatory variable, negative = outcome decreases with the explanatory variable). The magnitude of the association is indicated by the size of the coefficient (the larger the coefficient, the stronger the association). If the direction of the association is going in the wrong direction to that which we expect, this obviously indicates issues either in the theory or in the model, and if the magnitude of the effect is too small to be practically significant, then either the explanatory variable is not a good predictor of the outcome, or the model is not doing a good job of fitting the data (either the explanatory variable doesn’t really matter or the model is not capturing the true relationship between the explanatory variables and the outcome). However, while the direction is relatively easy to interpret, magnitude is not, because what counts as a practically significant effect is dependent on the context of the analysis.
7.3.2.2 Standard Errors
The standard errors are the standard deviation of the estimated coefficients. This is a measure of the precision of the estimated association between the explanatory variables and the outcome. The larger the standard error, the less precise the coefficient estimate. Precisely measured coefficients suggest that the model is fitting the data well, and we can be confident that the association between the explanatory variables and the outcome is real, and not just a result of random variation in the data. Defining what counts as ‘precise’ in any analysis, much like the coefficient magnitude, is dependent on the context of the analysis. However, in general, a standard error of less than 0.5 is considered to be a good estimate, and a standard error of less than 0.25 is considered to be a very precise estimate.
It is important to recognise that a precise coefficient alone cannot be treated as evidence of a causal effect between the explanatory variable and the outcome but it is, at least, a good indication that the explanatory variable is a good predictor of the outcome. In order to establish a causal relationship, we may consider methods that are more robust to the presence of confounding or ommitted variables, the gold standard being randomised controlled trials, but with a strong theoretical basis and a good understanding of the data, we can make a good case for a causal relationship based on observational data.
Gelman, Andrew, Jennifer Hill, and Aki Vehtari Vehtari. 2020. Regression and Other Stories. Cambridge University Press.
Source Code
# Linear Regression {#sec-linear-regression}{{< include _links.qmd >}}```{python}#| label: setup#| cache: false#| output: false#| code-fold: true#| code-summary: 'Setup Code (Click to Expand)'# packages needed to run the code in this section# !pip install pandas numpy matplotlib seaborn statsmodelimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsimport statsmodels.api as smfrom matplotlib import rc# data pathpath ='../data/'file_name ='deprivation.csv'# import datadf = pd.read_csv(f"{path}{file_name}")# set plot stylesns.set_style('whitegrid')# set plot fontrc('font',**{'family':'sans-serif','sans-serif':['Arial']})# set plot colour palettecolours = ['#1C355E', '#00A499', '#005EB8']sns.set_palette(sns.color_palette(colours))```Linear regression is a cornerstone of data science and statistical inference, and is almost certainly the most common statistical method in use today (t-tests might run it close in industry). Its popularity is owed to its incredible flexibility and simplicity, as it can be used to model a wide range of relationships in a variety of contexts, and it is both simple to use and to interpret. If there is one statistical method that every data scientist and analyst should be familiar with, it is linear regression (followed closely by logistic regression, which is closely related).Not only is linear regression a phenomenally useful tool in a data scientist's arsenal, but it is also a fantastic way to learn about the fundamentals of statistical inference. Linear regression serves as the perfect introduction to statistical inference, and it is a great starting point for learning about regression analysis because so many regression models are based on linear regression. Once you have a good understanding of linear regression, you can then move on to more advanced regression models, such as logistic regression, Poisson regression, and so on.For a really good, accessible introduction to linear regression, I'd highly recommend Josh Starmer's StatQuest video on the topic:{{< video https://www.youtube.com/watch?v=7ArmBVF2dCs >}}This tutorial will introduce you to linear regression in Python, using data pulled from two different sources. The first data source is the Public Health England's [Fingertips API]. The data included in this tutorial relates to health outcomes (life expectancy at birth) and deprivation (Indices of Multiple Deprivation (IMD) score and decile). The second data source is the Office of National Statistics' [Health Index], which is a composite measure of the health of the population in England. The Health Index is derived from a wide range of indicators related to three health domains: Healthy People (health outcomes), Healthy Lives (health-related behaviours and personal circumstances), and Healthy Places (wider drivers of health that relate to the places people live). The data included in this tutorial comes from two composite sub-domains in the Healthy Lives domain, which measure the physiological and behavioural risk factors that are associated with poor health outcomes. Both data sources are aggregated at the upper-tier local authority level, and the data covers the years 2015 to 2018.## Exploratory Data Analysis```{python}#| label: df-info# data summarydf.info()``````{python}#| label: df-head# view first five rowsdf.head()``````{python}#| label: summary-statsdf.describe()``````{python}#| label: deprivation-plot#| fig-align: center# imdsns.scatterplot(x='life_expectancy', y='imd_score', data=df)sns.despine()plt.show()``````{python}#| label: phsyiological-plot#| fig-align: center# physiological risk factorssns.scatterplot(x='life_expectancy', y='physiological_score', data=df)sns.despine()plt.show()``````{python}#| label: behavioural-plot#| fig-align: center# behavioural risk factorssns.scatterplot(x='life_expectancy', y='behavioural_score', data=df)sns.despine()plt.show()``````{python}#| label: life-expectancy-correlations# correlations with life expectancydf.corr(numeric_only=True).loc[:,'life_expectancy']``````{python}#| label: correlation-matrix# correlation matrixcorr = df[['life_expectancy', 'imd_score','physiological_score', 'behavioural_score']].corr()corr``````{python}#| label: correlation-plot#| fig-align: center# plot correlation matrixsns.heatmap(corr, cmap=sns.diverging_palette(220, 10, as_cmap=True), vmin=-1.0, vmax=1.0, square=True, annot=True)plt.show()```There are strong correlations between life expectancy and the three independent variables, however, the correlation between IMD score and the two risk factor variables is also relatively strong, and in the case of behavioural risk factors, it is very strong. This could be an issue.## Linear Regression```{python}#| label: model# create modelmodel = sm.OLS.from_formula('life_expectancy ~ imd_score + physiological_score + behavioural_score', data=df)# fit modelresults = model.fit()# print summaryprint(results.summary())```## Evaluating and Interpreting Regression ModelsWhen we fit a regression model, we have to consider both how well the model fits the data (evaluation) and the influence that each explanatory variable is having on the outcome (interpretation). The evaluation process is making sure that the model is doing a good enough job that we can reasonably draw some conclusions from it, while the interpretation process is understanding the conclusions we can draw. It's important to understand the purpose that both of these processes serve, and to understand that the evaluation process is just kicking the tires, while what we are ultimately concerned with is the interpretation.There are several elements to consider when interpreting the results of a linear regression model. Broadly speaking the focus should be on the magnitude and the precision of the model coeffficients. The magnitude of the coefficients indicates the strength of the association between the explanatory variables and the outcome variable, while the precision of the coefficients indicates the uncertainty in the estimated coefficients. We use the regression model coefficients to understand the magnitude of the effect and standard errors (and confidence intervals) to understand the precision of the effect.### Model EvaluationThere are a number of ways we might evaluate model performance, but the starting point should be the model's $R^2$ and the p-values of the model coefficients. These can help us consider whether the model fits the data and whether we have enough data to trust the conclusions we can draw from each explanatory variable.#### $R^2$The $R^2$ value is the proportion of the variance in the outcome that is explained by the model. It is often used as a measure of the goodness of fit of the model, and by extension the extent to which the specified model explains the outcome, but caution should be applied when using $R^2$ this way, because $R^2$ can be misleading and doesn't always tell the whole story. One of the main problems with $R^2$ when used in an inferential context is that adding more variables to the model will always increase the $R^2$ value, even if the new variables are not actually related to the outcome. Adjusted $R^2$ values are used to account for this problem, but they don't resolve all issues with $R^2$, so it is important to consider $R^2$ as just one of a number of indicators of the model's fit. If the $R^2$ is high, this doesn't necessarily mean that the model is a good fit for the data, but if the $R^2$ is particularly low, this might be a good indication that the model is not a good fit for the data, and at the very least it is good reason to be cautious about the results of the analysis, and to take a closer look at the model and the data to understand why the $R^2$ is so low.Defining high/low $R^2$ values is dependent on the context of the analysis. The theory behind the model should inform our expectations about the $R^2$ value, and we should also consider the number of explanatory variables in the model (adding variables to a regression will increase the $R^2$). If the theory suggests that the model should explain a small amount of the variance in the outcome, and the model has only a few explanatory variables, then a low $R^2$ value might not be a cause for concern.The Adjusted $R^2$ value for the above regression model is 0.843, which means that the model explains 84.3% of the observed variance in life expectancy in our dataset. This is a relatively high $R^2$ value.#### P-ValuesP-values are the probability of observing a coefficient as large as the estimated coefficient for a particular explanatory variable, given that the null hypothesis is true (i.e. that the coefficient is equal to zero), indicating that no effect is present. This can be a little tricky to understand at first, but a slightly crude way of thinking about this is that p-values are an estimate of the probability that the model coefficient you observe is actually distinguishable from zero.P-values are used to test the statistical significance of the coefficients. If the p-value is less than the significance level then the coefficient is statistically significant, and we can reject the null hypothesis that the coefficient is equal to zero. If the p-value is greater than the significance level, then the coefficient is not statistically significant, and we cannot reject the null hypothesis that the coefficient is equal to zero. The significance level is often set at 0.05, which means that we are willing to accept a 5% chance of incorrectly rejecting the null hypothesis. This means that if the p-value is less than 0.05, then there is a greater than 95% probability that the coefficient is not equal to zero. However, the significance level is a subjective decision, and can be set at any value. For example, if the significance level is set at 0.01, then we are willing to accept a 1% chance of incorrectly rejecting the null hypothesis.In recent years p-values (and the wider concept of statistical significance) have been the subject of a great deal of discussion in the scientific community, because there is a belief among many practitioners that a lot of scientific research places too much weight in the p-value, treating it as the most important factor when interpreting a regression model. I think this perspective is correct, but I think dismissing p-values entirely is a mistake too. The real problem is not with p-values themselves, but with the goal of an analysis being the identification of a statistically significant effect.I think the best way to think about p-values is the position prescribed by @gelman2020. Asking whether our coefficient is distinguishable from zero is the wrong question. As analysts, we should typically know enough about the context we are studying to build regression models with explanatory variables that will **some** effect. The question is how much. A statistically insignificant model coefficient is less a sign that a variable has no effect, and more a sign that there is insufficient data to detect a meaningful effect. If our model coefficients are not statistically significant, it is simply a good indication that we need more data. If the model coefficients are statistically significant, then our focus should be on interpreting the coefficients, not on the p-value itself.### Model InterpretationModel interpretation is the process of understanding the influence that each explanatory variable has on the outcome. This involves understanding the direction, the magnitude, and the precision of the model coefficients. The coefficients themselves will tell us about direction and magnitude, while the standard errors and confidence intervals will tell us about precision.#### Model CoefficientsThe model coefficients are the estimated values of the regression coefficients, or the estimated change in the outcome variable for a one unit change in the explanatory variable, while holding all other explanatory variables constant. The intercept is the estimated value of the outcome variable when all of the explanatory variables are equal to zero (or the baseline values if the variables are transformed).A regression's coefficients are the most important part of interpreting the model. They specify the association between the explanatory variables and the outcome, telling us both the direction and the magnitude of the association. The direction of the association is indicated by the sign of the coefficient (positive = outcome increases with the explanatory variable, negative = outcome decreases with the explanatory variable). The magnitude of the association is indicated by the size of the coefficient (the larger the coefficient, the stronger the association). If the direction of the association is going in the wrong direction to that which we expect, this obviously indicates issues either in the theory or in the model, and if the magnitude of the effect is too small to be practically significant, then either the explanatory variable is not a good predictor of the outcome, or the model is not doing a good job of fitting the data (either the explanatory variable doesn't really matter or the model is not capturing the true relationship between the explanatory variables and the outcome). However, while the direction is relatively easy to interpret, magnitude is not, because what counts as a practically significant effect is dependent on the context of the analysis.#### Standard ErrorsThe standard errors are the standard deviation of the estimated coefficients. This is a measure of the precision of the estimated association between the explanatory variables and the outcome. The larger the standard error, the less precise the coefficient estimate. Precisely measured coefficients suggest that the model is fitting the data well, and we can be confident that the association between the explanatory variables and the outcome is real, and not just a result of random variation in the data. Defining what counts as 'precise' in any analysis, much like the coefficient magnitude, is dependent on the context of the analysis. However, in general, a standard error of less than 0.5 is considered to be a good estimate, and a standard error of less than 0.25 is considered to be a very precise estimate.It is important to recognise that a precise coefficient alone cannot be treated as evidence of a causal effect between the explanatory variable and the outcome but it is, at least, a good indication that the explanatory variable is a good predictor of the outcome. In order to establish a causal relationship, we may consider methods that are more robust to the presence of confounding or ommitted variables, the gold standard being randomised controlled trials, but with a strong theoretical basis and a good understanding of the data, we can make a good case for a causal relationship based on observational data.## Next Steps## Resources- [MLU Explain: Linear Regression]- [StatQuest: Linear Regression]- [Regression & Other Stories]- [ModernDive: Statistical Inference via Data Science]- [A User's Guide to Statistical Inference and Regression]